2019 Spring, YBIGTA Conference 1st
2019 YBIGTA Conference에서 우리 팀이 1등을 수상했다. 우리 팀의 프로젝트 주제는 현실 영상을 애니메이션 스타일로 변환해주는 모델을 만들어보는 것이었다.
2017년에 개봉하여 흥행에 성공했었던 Loving Vincent(2017) 에서 아이디어를 착안하여 팀원들과 이 프로젝트를 시작하게 되었다. 러빙빈센트의 경우 107명의 화가가 약 2년 동안 65,000프레임에 달하는 양을 작화했다. 실제 영화를 찍은 뒤, 이를 그림으로 그려내는 작업에 아주 많은 시간과 자원, 노력이 들어간 것이다. 만약 Style Transfer Model이 잘 작동하여 이를 수행해준다면, 혹은 그림으로 그려내는 작업의 밑바탕이 되어준다면 좋지 않을까라는 생각이었다.
Style Transfer
기본적인 Style Transfer 기본적인 Idea를 살펴보자.
Style을 적용하고자 하는 content image와 style image를 네트워크에 통과시킬 때 Feature Map을 얻을 수 있다. 이 각각의 feature map을 바탕으로 새롭게 합성될 영상의 feature map이 비슷하도록 최적화하는 과정을 Style Transfer 라고 할 수 있다.
Model searching
사실 작년에 KT ATC에서 다양한 프로젝트를 진행하면서 Image에 대한 Style Transfer Model(Vanilla gan, DCGAN, Cycle GAN 등)은 많이 접해보았지만, Video의 Style Transfer는 처음 접해보는 부분이었다.
처음 떠오른 모델은 GAN이였고, 역시 최종적으로 사용한 모델 또한 GAN이었다. 하지만 GAN의 재현성 문제 때문에 조금 더 안정적인 모델이 있지 않을까 하는 생각에 다른 model 또한 searching해 보았다.
모델 Searching 과정에서 NVIDIA & MIT의 Video-to-Video Synthesis 등의 모델을 찾았지만 Paired Dataset에 대해서만 학습이 가능하다는 한계가 있었다. 우리 팀이 직접 Paired Dataset을 만들 수는 없는 상황이었으므로 안타깝게도 이 모델은 사용할 수 없었다. GAN based model이 아닌 다른 여러 Style Transfer 모델들 또한 Video가 아닌 Image에 대한 연구가 대부분이었다.
결과적으로 우리는 Artistic Style Transfer for Videos(2016) 과 GAN Based Model인 Learning Linear Transformation for Fast Image and Video Style Transfer(2019) 를 중심으로 문제를 해결해보기로 했다.
1. Artistic Style Transfer for Videos(2016)
우리가 선택한 첫 번째 모델은 Artistic Style Transfer for Videos(2016, Cornell University)이다.
이 논문에 대한 간단한 설명을 덧붙이면 다음과 같다.
- Image style transfer를 video sequence style transfer로 확장하였음.
- artistic image를 특정 style로 변환하여 영상 전체에 painting.
- Transfer를 정규화하고, 프레임 간의 자연스러운 전환을 위하여 두 프레임 사이의 편차를 penalize하는 temporal constraint.
논문을 읽었을 때 우리 프로젝트의 목적과 잘 부합해 보이는 모델이라는 생각이 들었다. 하지만 문제는…
Lua
이 논문의 저자가 git에 paper code를 공개해놓았는데, Lua로 만들어진 모델이었다.(https://github.com/jcjohnson/neural-style)
시간이 많았다면 Pytorch로 직접 구현해 보았을 텐데, 시간이 없어 직접 논문을 구현하기 보다는 Lua를 공부하는 것이 더 빠르겠다는 판단이 들었다. Pytorch, tf에만 익숙했었기 때문에, Lua 공부하자고 결심하기까지는 큰 결심이 필요했다.
결국 output을 만들어 내는데 성공했다. 물론 Lua에 익숙하지 않아 기본적인 setting에서 모델을 사용했지만, Image를 Input으로 사용했을 때에는 꽤나 성능이 잘나왔다. 우리 연구실의 대표 미남 연구원을 Input Image로 사용하여 van gogh 의 starry night 의 Style로 Image Style Transfer를 해보았다.
이 모델을 Video에도 적용해 보았다. training 시간은 프레임당 약 70초로, 20초짜리 동영상(약 500 Frames)을 Training 시키는데 약 10시간이 걸렸다.

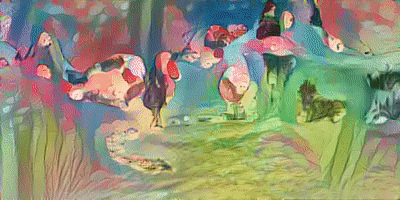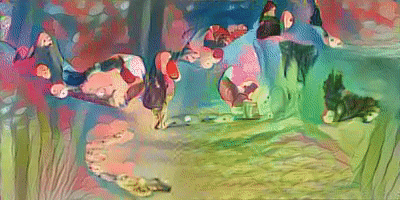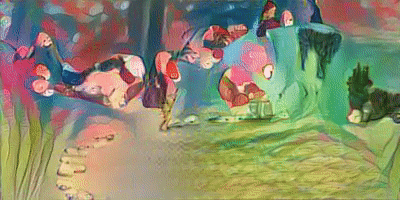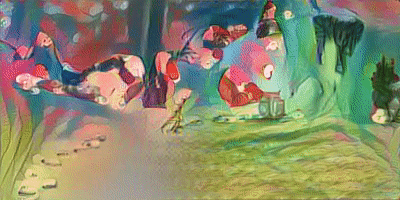

가장 왼쪽의 Video가 원본 영상이며, 차례대로 벼랑위의포뇨 와 김홍도 스타일로 해당 영상을 변환해본 모습이다. 처음엔 나름 생각보다 괜찮은 성능을 보여서 놀랐다.
하지만 다양한 input videos를 통해 test해보던 중 문제점을 발견하게 되었다.

알라딘 예고편에 모델을 적용해보았는데, 잔상이 매우 심하게 남아 output이 뭉개지는 현상이 나타났다. Image to Image 모델에서 발전된 이 모델의 특성 상, 자연스럽게 연결을 위해 Temporal Constraint 알고리즘을 사용하였다. 아마도 이 때문에 결과적으로 잔상이 매우 심하게 남게 된 것이지 않을까하는 생각이 들었다.


스파이더맨 예고편 영상에도 해당 모델을 적용해보았다. 나름 괜찮긴 한데 전체적으로 뭉개지는 건 어쩔 수 없는 모델의 한계인 듯 했다.
2. Learning Linear Transformation for Fast Image and Video Style Transfer(2019)
2019 CVPR에서 발표된 Learning Linear Transformation for Fast Image and Video Style Transfer 를 최종적인 모델로 선택하게 되었다. 아무래도 이 모델은 이미 우리에게 익숙한 Pytorch로 구현되어 있었으며, 제한된 시간 내에 다양한 시도 및 앙상블이 가능했기 때문에 이 모델을 최종적으로 선택하게 되었다.
이 모델의 경우 데이터 중심의 transformation matrix를 학습하는 universal style transfer이며, 또한 Content 연결성을 보존하는 효율적이고 유연하다는 특징이 있다.

풍경을 담은 동영상을 테스트 input으로 사용해 보았다. 앞서 살펴본 모델에 비하여 속도도 매우 빨라졌으며, 20초 동영상을 training하는데 약 38.5초 밖에 걸리지 않았다. Training 속도, ouput 모두 월등한 성능을 보여서 해당 모델을 프로젝트의 base model로 활용하게 되었다.
역시 스파이더맨 영상에 적용해보았다.

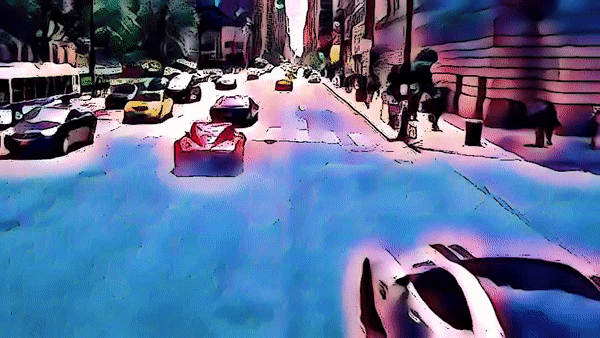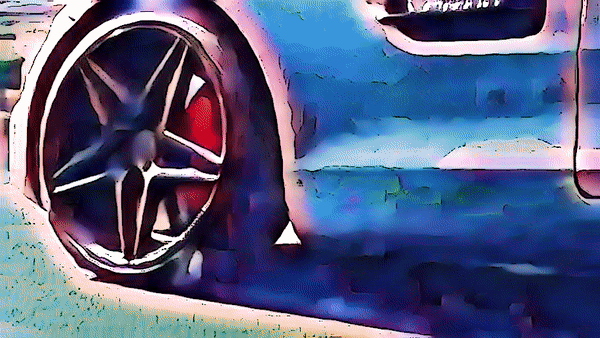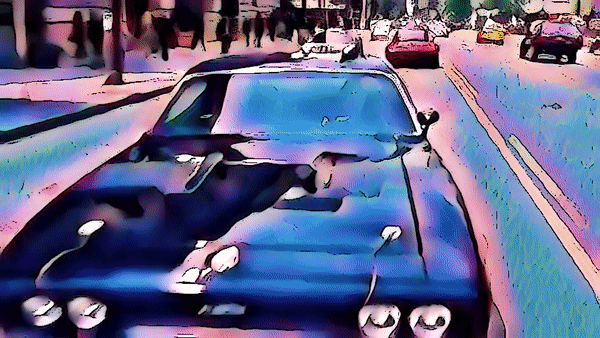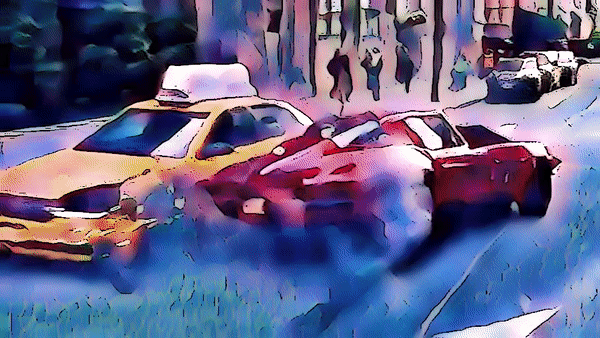
3. Edge Detection
Boundary가 분명한 애니메이션의 특성을 고려한다면, Edge Detection을 적용하여 output의 경계선을 뚜렷하게 만들어준다면 조금 더 실제 애니메이션에 가깝게 보이지 않을까하는 아이디어였다.
Sobel, Canny, Lplacian 3가지 Edge Detection 방법 중 가장 성능이 좋은 Laplacian Edge Detection을 사용하였다.


왼쪽은 Style Transfer model의 output이고, 오른쪽은 왼쪽의 output에 Edge Detection을 적용해준 결과다.
4. Output
우리는 앞의 Learning Linear Transformation for Fast Image and Video Style Transfer(2019) 와 Edge Detection 을 앙상블하여 최종 모델을 만들었다. 최종 Output은 다음과 같다.

