Batch Processing
‘데이터처리를 한다’는 말을 할 때, 보통 어떤 데이터 처리방식이 떠오르는가? 보통 이제껏 우리가 다루어 온 데이터처리 방식은 고정된 과거의 데이터 를 한 번에 처리하는 방식이다. 이와 같은 방법을 Batch 처리 라고 한다.
일반적인 Batch 처리의 특징은 다음과 같다.
-
고정된 input 데이터를 처리한다.
-
데이터의 크기가 크다.
-
대상 시간의 범위가 넓다.(짧게는 몇 시간, 길게는 몇 일이 되기도 한다)
-
데이터처리 중 실패하더라도 다시 결과를 만들어낼 수 있다.
-
데이터 생성 시점과 데이터 처리 시점 사이의 시간적 간격이 크다.
Stream Processing
하지만 우리의 실생활을 둘러보면 이러한 성격과는 어울리지 않는 데이터들이 분명 존재한다. 미세먼지농도에 대한 정보, 교통 흐름 정보, 실시간 검색 정보 등을 그 예로 들 수 있을 것이다. 이러한 데이터들의 경우, 최대한 빠른 시간 내에 데이터 분석을 하여 output을 만들어내야 한다.
Streaming 이란 신규 데이터를 끊임없이 처리하여 결과를 만들어내는 방식이다.
Streaming 처리의 특징을 살펴보면 다음과 같다.
-
무한하게 입력되는 데이터를 처리한다.
-
Input data의 시작과 끝이 정의되어 있지 않다.
-
새로운 데이터가 입력될 때 마다 새로운 결과를 만들어낸다.(실시간 처리)
Spark Streaming
Spark Streaming 은 실시간 으로 변하는 데이터를 짧은 주기 에 맞춰 빠르고 안정적으로 처리하는데 필요한 기능을 제공하는 Spark의 Sub-module이다. 이러한 성격때문에 Spark Streaming은 실시간으로 데이터처리가 필요하거나 의사결정이 필요한 분야에서 많이 사용되고 있다.

위 그림은 Spark Streaming을 활용한 데이터처리의 전체적인 구조를 나타낸 것이다.
간단하게 살펴보면 Kafka, Flume, HDFS/S3, Kinesis, TCP Socket 등의 다양한 경로로 input data가 주어질 수 있다. 이를 map, reduce 등의 연산을 사용하여 데이터처리를 하고, 다시 HDFS나 DB 등에 적재하는 구조를 가지고 있다.
스파크의 스트리밍은 짧은 주기의 배치처리를 하는 것이다. 짧은 주기의 배치처리 때문에 배치 작업 사이에 새로 생성되는 데이터 크기를 최소화시킬 수 있다. 참고로 스파크 스트리밍에서는 이렇게 새로 생성된 데이터가 하나의 RDD로 취급되어 처리된다. 이제 실제로 어떻게 스트리밍 모듈을 사용할 수 있는지 살펴보자.
from pyspark import SparkContext, SparkConf, storagelevel
from pyspark.streaming.context import StreamingContext
sc = SparkContext(master="local", appName="Name", conf=conf)
ssc = StreamingContext(sc, 3)
스트리밍 모듈을 사용하기 위해서는, StreamingContext 인스턴스를 생성해야 한다. StreamingContext 인스턴스의 두 번재 인자는 데이터를 읽어와서 RDD를 생성하는 주기를 뜻한다.(즉, 이 경우에는 3초 마다 데이터를 읽어와서 RDD를 생성하는 것이다.)
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext=False)
StreamingContext는 start(), awaitTermination(), stop()라는 명시적인 시작, 대기, 종료 메서드가 필요하다. 만약 StreamingContext를 종료하면서 SparkContext를 종료하고 싶지 않다면 위와 같은 옵션을 사용할 수 있다.
StreamingContext는 일단 시작되면 새로운 연산을 추가할 수 없으며, 종료되는 순간 재시작할 수 없다. 또한, JVM 하나당 하나의 StreamingContext만 사용할 수 있다는 특징을 가지고 있다.
API of Spark Streaming
Spark는 ‘Dstream’과 ‘Structured Streaming’이라는 2가지의 Streaming API를 제공한다. 두 가지 Streaming API의 특징은 다음과 같다.
- 이벤트 시간 기준 처리: data source에서 레코드에 기록한 타임 스탬프를 기반으로 데이터 처리
-
처리 시간 기준 처리 : Streaming Application에 레코드가 도착한 타임 스탬프를 기반으로 데이터 처리
- 마이크로 배치 처리: 입력 데이터를 끊임 없이 처리하는 것이 아닌, 하나의 작은 배치가 모일 때까지 기다렸다가, 다수의 분산 테스크를 사용하여 각 배치를 병렬적으로 처리.
- 한 노드당 더 높은 처리량을 가진다.
- 동적인 부하 분산 기술이 사용 가능하다.
- 단, 하나의 단위 배치 데이터를 모으기 위한 시간 지연이 존재한다.
- 연속형 처리: 각 노드가 다른 노드에서 전송하는 데이터를 끊임없이 수신. 갱신된 정보는 레코드를 하나씩 하위노드로 전달.
- 전체 input의 양이 적으면 매우 빠르지만, 부하가 매우 크다.
Dstream
Dstream은 Discretized Streams의 줄임말이다. 우선, 일정 시간동안 데이터를 모아서 하나의 작은 RDD를 만든다. 이러한 RDD들이 모인 Sequence를 바로 Dstream이라고 부른다.
Dstream은 마지막으로 데이터를 읽은 시점부터 배치 간 간격에 해당하는 시간동안 새로 발생한 데이터들을 다시 RDD로 만드는 과정을 반복한다.
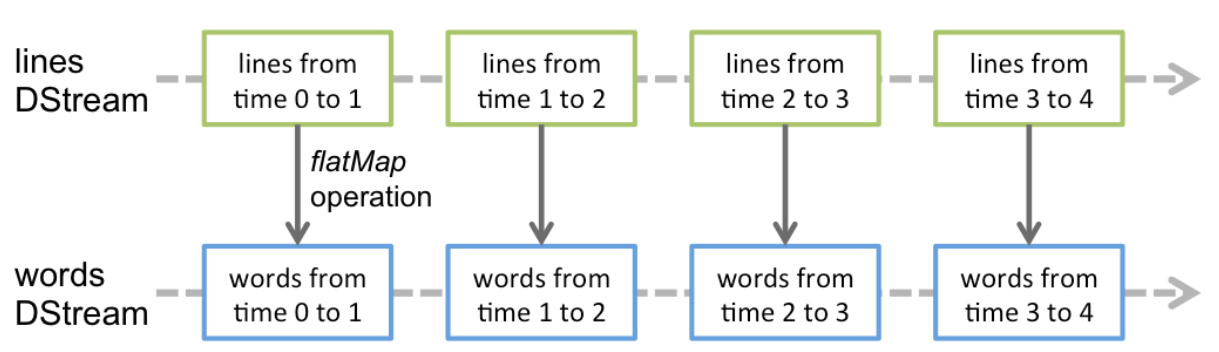
Dstream은 새로운 Dstream 생성하는 연산과 외부 시스템에 데이터를 보내는 연산을 제공한다. 이는 RDD의 transformation, action 연산과 같다고 볼 수 있다.
Dstream의 단점을 살펴보면 다음과 같다.
- Python, Java, Scalar, R의 객체와 함수에 의존적
- 이벤트 시간 기준 처리 지원 X
- Micro 배치 방식으로만 작동
Reference
Spark The Definitive Guide(스파크 완벽 가이드)
image: streaming-programming-guide