Structured Streaming(구조적 스트리밍)
Structured Streaming은 Spark의 구조적 API를 기반으로 하는 고수준 스트리밍 API이다. 앞서 살펴본 Dstream API의 단점을 보완하여 더욱 발전시킨 것이 Structured Streaming이라고 생각하면 된다.
구조적 스트리밍의 기본적인 특징은 다음과 같다.
- 확장가능하고 내고장성(fault tolerance)을 가진 Spark SQL 엔진에 구축된 스트림 처리 엔진
- 스트리밍 연산은 정적 데이터에 대한 배치 연산을 표현하는 것과 비슷한 방식으로 표현 가능
- Spark SQL 엔진은 증분형으로 끊임없이 실행하며 스트리밍 데이터가 도착할 때마다 최종 결과를 업데이트
- Scala, Java, Python, R 에서 DataFrame/Dataset API를 사용하여 스트리밍 집계, 이벤트 시간 윈도우, 스트림-배치 조인 등을 표현 가능
Structured Streaming의 가장 기본이 되는 컨셉은 데이터 스트림을 ‘데이터가 연속적으로 추가되는 테이블’처럼 다루는 것이다.
구조
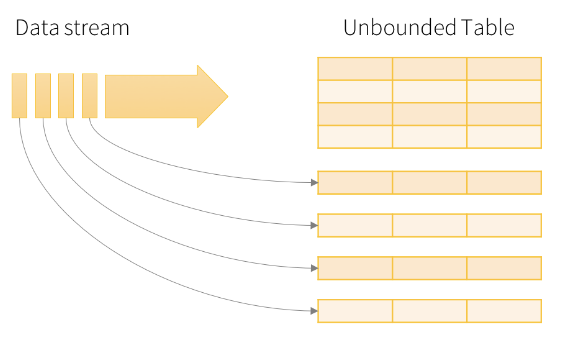
우리는 data stream을 Ubounded input table로 생각할 수 있다. 즉, input으로 데이터 스트림이 새로 추가될 때 마다 Input Table의 하나의 row로 들어가게 되며, 이러한 rows가 무한히 많이 추가될 수 있는 구조를 가지고 있다고 생각하면 된다.
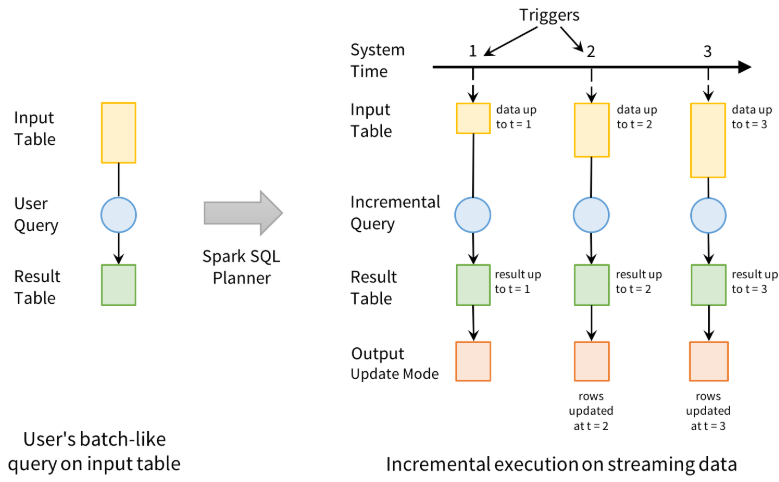
개발자는 입력 테이블이 마치 정적 테이블인 것처럼 생각하여 출력 싱크에 작성될 최종 결과 테이블(result table)을 정의하는 쿼리를 정의한다.
Spark는 자동으로 이 쿼리를 스트리밍 실행 계획으로 전환하며, 이후에 레코드가 도착할 때마다 결과를 업데이트하는 데 필요한 상태를 파악하게 된다.
마지막으로 개발자는 트리거를 설정하여 언제 결과를 업데이트할지 제어한다. 트리거가 실행될 때마다 Spark는 새로운 데이터를 확인하고, 결과를 증분형으로 업데이트한다.
구조적 스트리밍은 소스로부터 스트림 데이터를 읽어들이고, 증분형으로 처리하여 결과를 업데이트한 후, 소스 데이터를 버린다. 결과 업데이트에 필요한 최소한의 중간 상태 데이터만 보관하는 것이다.
결과 테이블이 업데이트될 때마다 외부 시스템(예를들어 HDFS, DB)에 그 변화를 기록하고, 증분형으로 출력하게 된다.
Input Source
Structured Streaming에는 소켓(socket), 파일, RDD 큐, Kafka와 같은 다양한 입력 소스를 사용할 수 있다. 이 중, 주로 Testing용으로 사용되는 Socket과 File의 케이스에 대하여 예시와 함께 자세히 살펴보도록 하겠다.
1. Socket
TCP 소켓을 이용하여 Input data를 수신할 수 있다. option(“host”, “localhost”), option(“port”, 9000)을 통해 IP주소와 포트번호(9000)를 지정하여 스파크 스트리밍의 Data Source로 사용할 수 있다. 다음은 Socket을 Data source로 사용하는 예시다.
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9000) \
.load()
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
query.stop()
위 코드를 실행하기 전에 새로운 Terminal에서 nc -lk 9000 을 실행한 후에 data를 입력하면 성공적으로 dataframe이 생성되는 것을 확인할 수 있다.
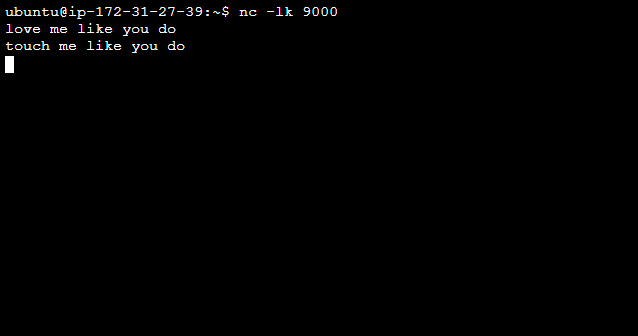

위와 같이 새로운 Terminal에서 input data를 입력해주면, input data에서 단어의 수를 count한 내용을 담은 dataframe을 생성하는 것을 확인할 수 있다.
다만 소켓이 드라이버에 있어 종단 간 내고장성을 보장할 수 없으므로 실제 운영 환경에서 사용하면 안 되며, Testing용으로만 사용해야 한다.
2. File
반면, 데이터 소스로 파일을 사용할 수도 있다. 다만 파일을 데이터 소스로 사용할 경우 주의해야 할 점은 스파크 스트리밍은 파일의 변경 내용까지 추적하지는 않는다는 것이다.
즉, 동일 디렉토리 내의 파일은 모두 같은 형식 이어야 하며, 읽는 시점에 따라 파일내용이 변경되면 안된다는 점을 기억해야 한다.
파일 형식은 pqrauet, text, json, csv, orc이 지원되며, 모든 파일은 설정해준 path에 원자적으로 추가되어야 한다.
다음은 csv 파일을 data source로 사용하는 예시다.
spark = SparkSession.builder \
.appName("csvDF") \
.master("local[*]") \
.getOrCreate()
userSchema = StructType().add("1st", "integer").add("2nd", "integer").add("3rd", "integer")
csvDF = spark.readStream \
.option("sep", ",") \
.schema(userSchema) \
.csv("hdfs:/ybigta/191116")
query = csvDF.writeStream \
.outputMode("update") \
.format("console") \
.start()
query.awaitTermination()
query.stop()
이번에는 위 코드를 실행한 후, 위 코드에서 설정해준 hdfs path에 data file을 put해보자.
hadoop fs -put [local 경로] [hdfs 경로]
해당 hdfs path로 데이터가 전송되면, 다음과 같이 datafame이 생성되는 것을 확인할 수 있다.

덧붙여, 다음은 기본적인 hdfs 명령어이므로 기억해두자.
hadoop fs -ls
hadoop fs -mkdir
hadoop fs -rm
Reference
Spark The Definitive Guide(스파크 완벽 가이드)