응용
앞서 Basic Operation을 통하여 데이터스트림을 읽어 dataframe을 만들어 보았다. 이번 포스트에서는 두 예제를 통하여 데이터스트림을 읽은 뒤 집계함수와 사칙연산을 활용하여 Input Dataframe을 바꾸는 법을 살펴보도록 하자.
example 1. select, where
먼저 새로운 Terminal에서 nc -lk 9000 을 입력한 뒤, 소켓으로 Input Data를 입력해보자.
spark = SparkSession.builder \
.appName("character") \
.master("local[*]") \
.getOrCreate()
lines = spark.readStream.format("socket") \
.option("host", "localhost") \
.option('port', 9000) \
.load()
character = lines.select("value").where("value > 'c'")
query = character.writeStream \
.outputMode("update") \
.format("console") \
.start()
query.awaitTermination()
query.stop()
이전 포스트에서 살펴본 Word Count예시에 select를 적용해보았다. character 변수를 정의할 때, 첫 글자의 ascii code가 ‘c’보다 큰 character만 선택하도록 정의해주었다.
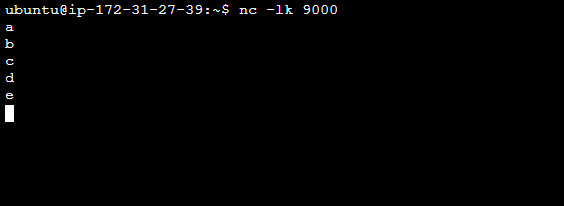
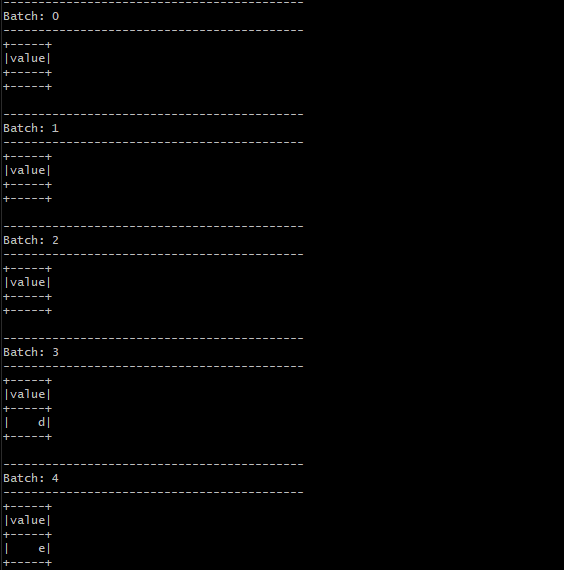
결과적으로 ‘c’보다 ascci code가 크지 않은 ‘a’,’b’,’c’는 선택되지 않았고, ‘d’, ‘e’만 선택되었음을 확인할 수 있다.
example 2. Arithmetic Operation
이전 포스트에서 csv파일을 hdfs path로 put하는 예제를 조금 수정한 것이다.
spark = SparkSession.builder \
.appName("addition") \
.master("local[*]") \
.getOrCreate()
userSchema = StructType().add("1st", "integer").add("2nd", "integer").add("3rd", "integer")
csvDF = spark.readStream \
.option("sep", ",") \
.schema(userSchema) \
.csv("hdfs:/ybigta/191116/")
addition = csvDF.select(col("1st")*2, col("2nd")+1)
query = addition.writeStream \
.outputMode("update") \
.format("console") \
.start()
query.awaitTermination()
query.stop()
받은 데이터에서 첫 번째 열에 2를 곱하고, 두 번째 열에 1을 더한 값을 select해주었다. 다음은 결과 dataframe이다.
(input data는 1열에 [1,2,3,4,5,6,7,0], 2열에 [1,2,3,4,5,6,7,0]이 있는 8x2 csv file이다.)

Reference
Spark The Definitive Guide(스파크 완벽 가이드)