3. Stacking
Stacking은 Stacked Generalization이라고도 불린다. Stacking은 다른 여러 알고리즘의 예측 결과를 결합하여 새로운 알고리즘을 학습하는 과정을 의미한다. 학습 과정을 간단하게 설명하면 다음과 같이 2-stage로 나눌 수 있다.
(stage 1) Data를 통해 각각의 다른 알고리즘들을 학습한다.
(stage 2) stage 1에서 만든 알고리즘들의 예측 결과를 추가적인 input으로 사용하여 Combiner algorithm (혹은 meta classifier)을 만들고, 이를 통하여 final prediction을 구한다.
사실 이렇게 설명하면 이해하기가 쉽지 않다. 이해하기 쉽도록 이곳을 참고하여 전체적인 과정을 직접 그려보았다.
기본적인 stacking의 아이디어를 도식화한 그림이다. 단계별로 살펴보도록 하겠다.
(1) 데이터셋 나누기
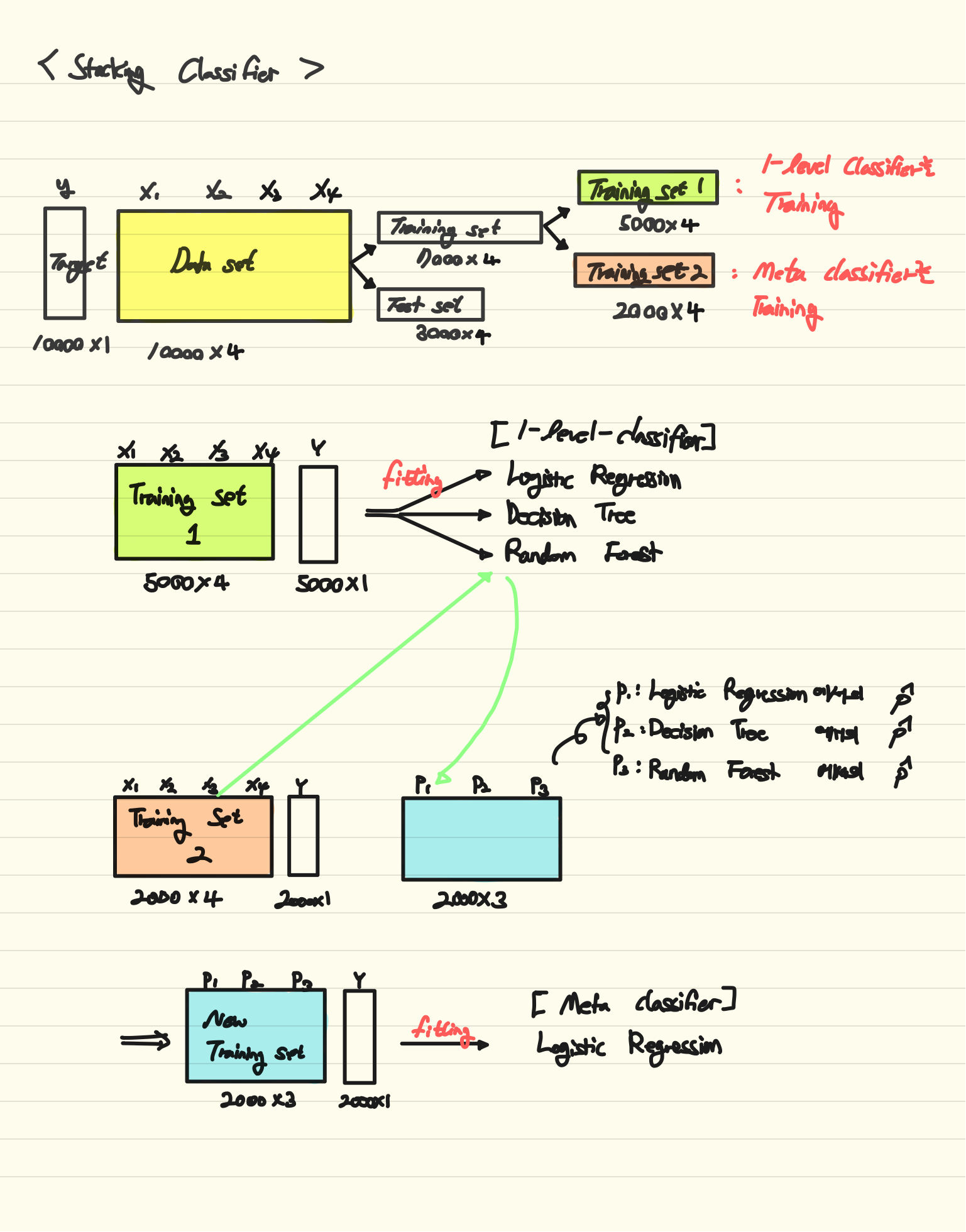
우리에게 10000x4의 Training data($x$)와 10000x1의 Target data($y$)가 주어졌다고 가정하자.
우선, 일반적으로 7:3의 비율로 dataset을 나눌 수 있으로 7000x4의 training set과 3000x4의 test set으로 나누게 된다. 이 training set을 다시 한 번 training set1과 training set2로 나눌 수 있는데, training set1은 1-level classifier를 학습시킬 때 사용할 데이터이고, training set2는 최종 모델인 meta classifier를 학습시킬 때 사용할 데이터가 된다.
(2) 1-level-classifiers 학습
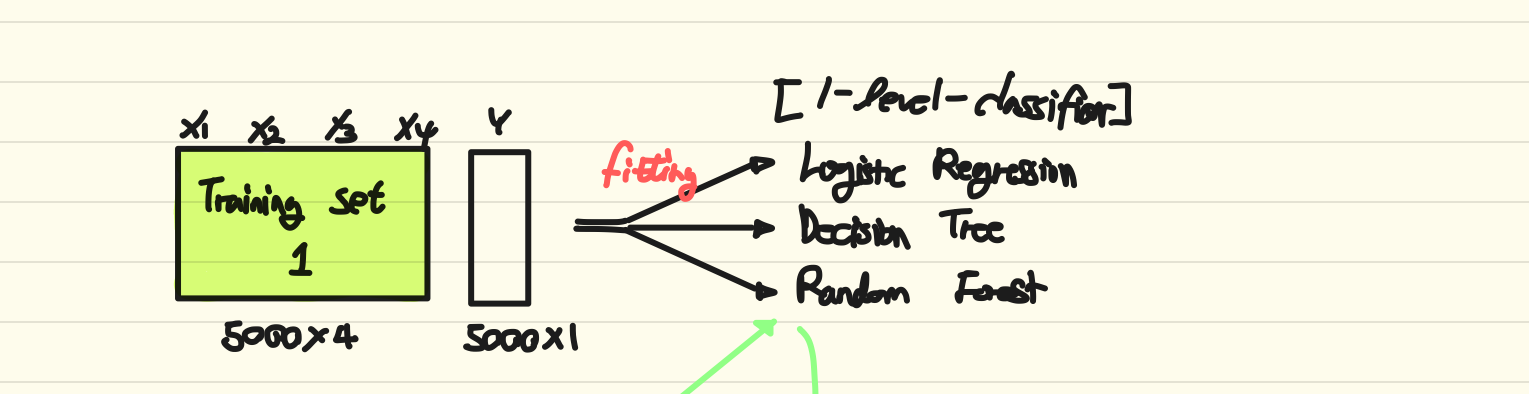
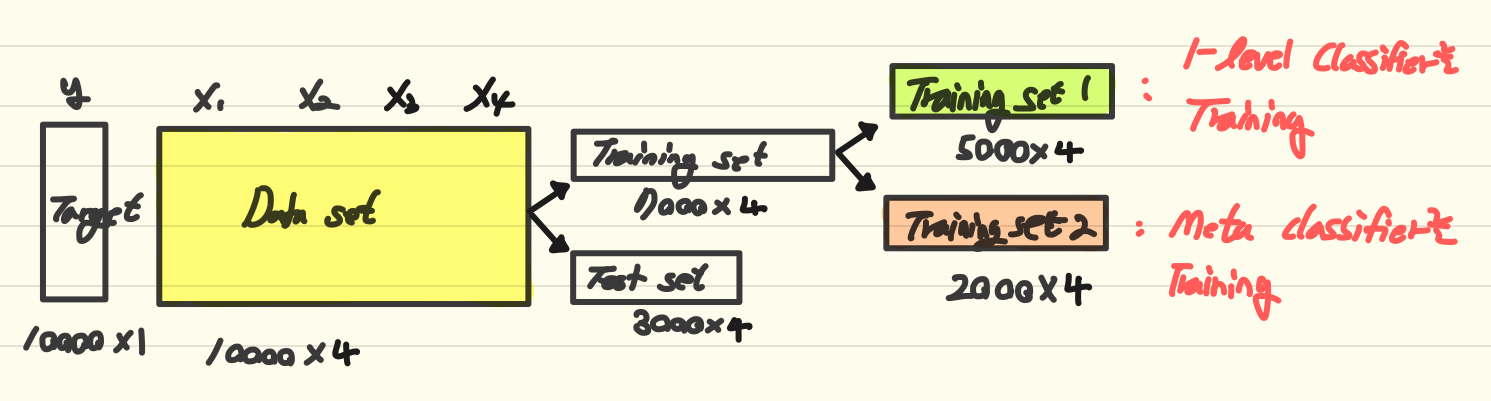
앞서 나눈 Training set 중, Training set1을 통하여 여러 모델을 학습시킨다. 이 예시에서는 세 가지 classification models를 학습시켰다.
(3) meta-classifier의 training data 만들기
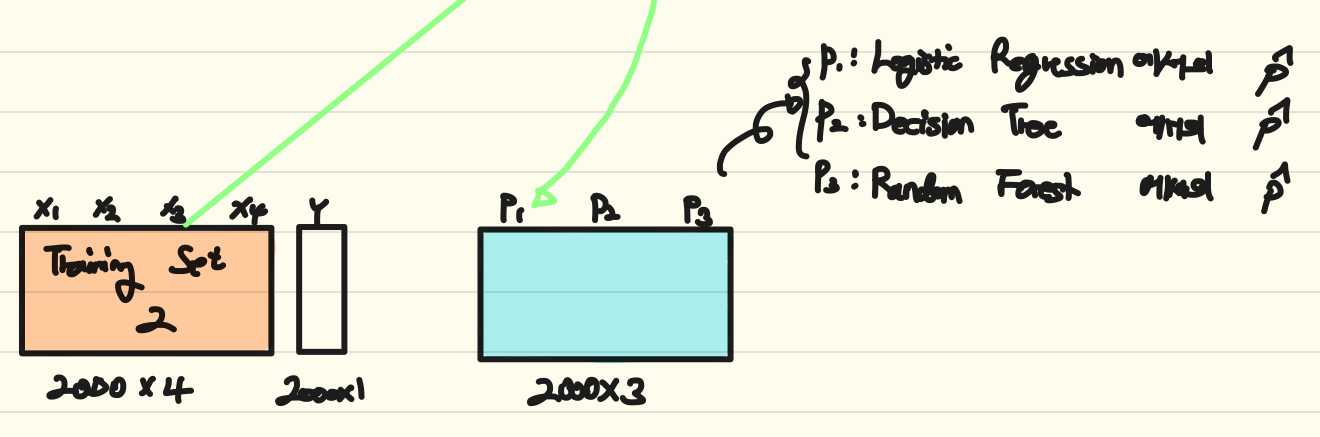
앞서 만든 여러 모델들에 Training set2를 input으로 주었을 때, class에 대한 예측 확률($\hat p$)을 얻을 수 있다. 이렇게 각 model마다 해당 class에 대한 확률 값을 얻을 수 있을 것이다. 이렇게 세 모델에서 얻은 예측 확률들로 2000x3의 dimension을 가진 [p1, p2, p3] 행렬을 만든다.
(4) meta-classifier 학습

이렇게 만든 [p1, p2, p3] 행렬을 meta classifier의 training dataset으로 사용하여 최종 모델을 학습시킨다.
Reference
Bhavesh Bhat(2019), Stacking Classifier | Ensemble Classifiers | Machine Learning