각 class 간의 불균형 상태(One class in the training set dominates the other)는 분류 알고리즘의 성능에 큰 영향을 미칠 수 있다. 이를 해결하기 위하여 다양한 아이디어가 고안되었는데, 이번 포스트에서는 SMOTE(Synthetic Minority Over-sampling Technique) 에 대해 살펴보도록 하겠다.
Imbalanced data, Classification
IRIS dataset을 예시로 Imbalanced data에 대해 살펴보도록 하겠다. IRIS dataset에는 ‘sepal length(cm)’, ‘sepal width(cm)’, ‘petal length(cm)’, ‘petal width (cm)’의 총 4개의 feature와 ‘setosa’, ‘versicolor’, ‘virginica’ 총 3개의 class가 존재한다. 4개의 feature를 통하여 class를 예측하는 prediction 문제를 풀어보고자 한다.
Imbalanced data의 문제점을 살펴보기 위하여 다음과 같은 극단적인 예시를 들어보자. IRIS data 중 Sepal_length, Sepal_width 두 개의 열과, 일부 행을 가져와서 plot을 그려보면 다음과 같다.
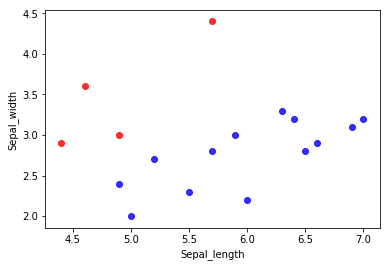
해당 dataset에는 총 17개의 observation이 존재한다.(class A: 13개, class B: 4개) 위 plot에서 확인할 수 있듯이, 이 dataset은 명확하게 Imbalanced dataset이며, 해당 데이터셋으로 classification 모델을 적합시킬 경우 다소 문제가 발생할 수 있다.
심지어 아래 그림과 같이 class B의 각 axis에 대한 최소/최대 값 범위에서 살펴보더라도 class A observation의 수가 더 많다는 사실을 알 수 있다.
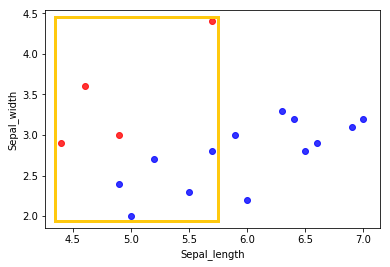
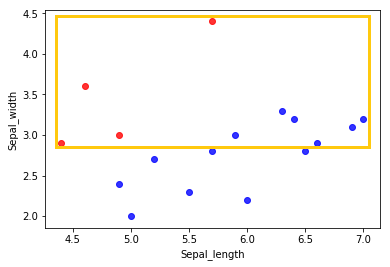
이러한 imbalanced dataset에서는 단순히 17개의 모든 class를 일괄적으로 class A로 예측하더라도 Accuracy 82%의 예측 결과를 얻을 수 있다. 즉, classification 모델의 성능에 도움이 되지 않는 것이다.
이러한 imbalaced data 문제를 해결하기 위한 방법으로는 크게 다음 4가지 방법이 존재한다.
-
Synthesisis of new minority class instances
-
Over-sampling of minority class
-
Under-sampling of majority class
-
tweak the cost function to make misclassification of minority instances more important than misclassification of majority instances
엄밀하게 말하자면 SMOTE는 1번에 해당하는 방법이라고 볼 수 있다. SMOTE는 데이터의 수가 부족한 minority class의 수를 늘리고, 이를 통해 각 class 별 데이터의 수를 적절하게 맞춰줌으로써 imbalanced data 문제를 해결할 수 있게 된다.
SMOTE
SMOTE에서는 SMOTE pecentage(percentage fo Oversampling)를 설정해주어 minor class의 observation 수에 비하여 얼마나 많은, 혹은 적은 수를 더 샘플링할 것인지를 선택할 수 있다. 간편함을 위하여 여기서는 SMOTE percentage를 100%로 가정하고 source code를 구현해 보았다.
SMOTE에 대한 과정을 간단하게 정리보면 다음과 같다.
-
minor class의 observations의 개수를 T개라고 하자.
-
for문을 통하여 아래의 3-8의 steps를 $i=1,2,\cdots,T$에 대하여 반복한다.
-
$i$번째 observation인 $X_i$에 대하여 $k$개의 nearest-neighbors를 선택한다.
-
$k$개의 observations 중, 1개의 observation $X_j(j \neq i)$을 random하게 선택한다.
-
$X_i$와 $X_j$ 사이의 Euclidean distance를 구한다.
-
Uniform(0,1) 분포에서 weight를 생성한다.
-
step 5에서 구한 Euclidean distance와 step 6에서 구한 weight를 곱하여 $X_i$에 더해준다.
-
step 7에서 생성된 데이터셋을 새로운 데이터셋에 추가한다.
SMOTE source code
다음은 SMOTE를 파이썬으로 간단하게 구현한 것이다. 아래 SMOTE 함수의 input $X$는 minor class에 해당하는 index의 training dataset이다.
def k_nearest_neighbor(X, x, k):
X_len = len(X)
euclidean_dist = []
for j in range(X_len):
if np.array_equal(X[j], x) == 0:
euclidean_dist.append(np.sqrt(sum((X[j]-x)**2)))
euclidean_dist = np.sort(euclidean)
euclidean_nearest = euclidean_dist[:k]
idx_random = np.random.multinomial(1, [1/k]*k) == 1
euclidean_nearest = euclidean_nearest[idx_random]
w = 0
while w == 0:
w = np.random.uniform(0,1)
add = euclidean_nearest*w
return(add)
def SMOTE(X,k):
X_len = len(X)
imputed = []
for i in range(0,X_len):
add = k_nearest_neighbor(X,X[i],k)
impute = X[i] + add
imputed.append(impute)
return imputed
Reference
Application of Synthetic Minority Over-sampling Technique (SMOTe) for Imbalanced Data-sets