Computer Vision Tasks
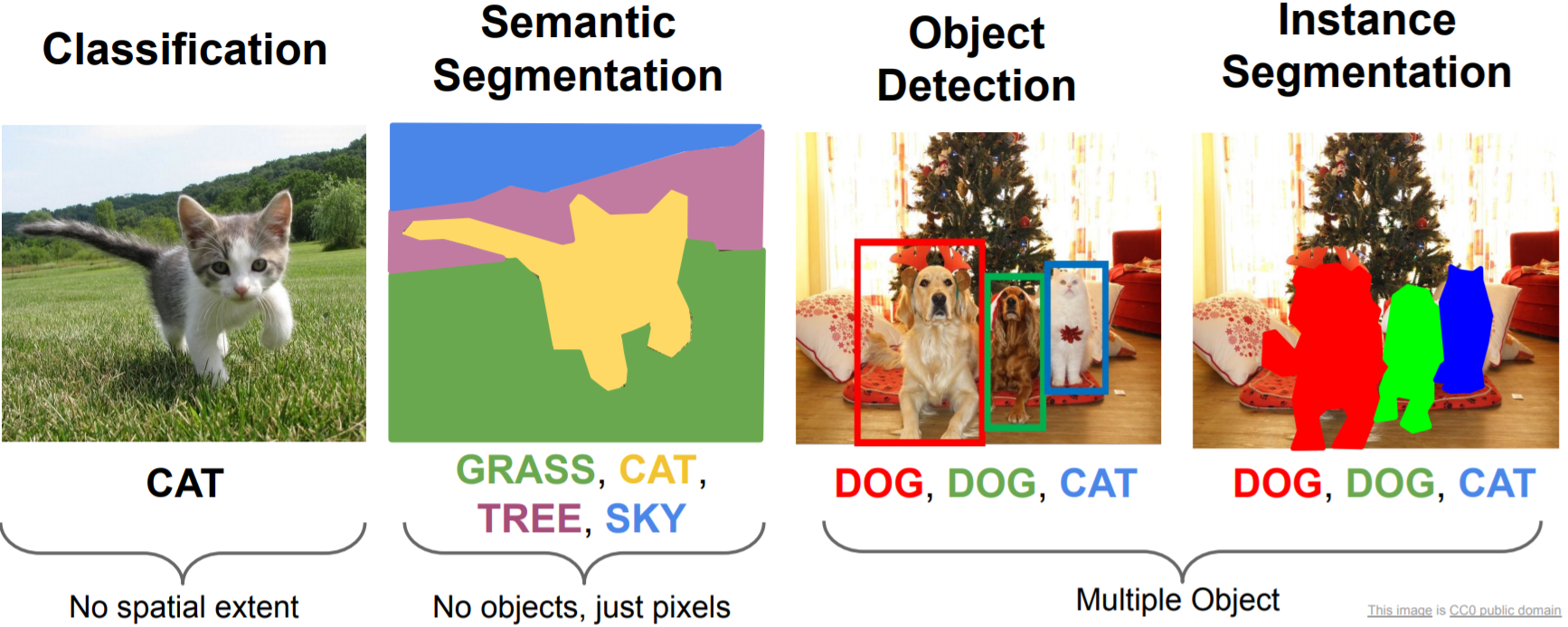
Computer Vision에서 주로 다루게 되는 문제들은 크게 Classification/Sementic Segmentation/Object Detection/Instance Segmentation과 같이 4가지로 분류할 수 있다.
이 중, 이번 포스트에서는 Classification(Image Recognition) 문제에서 주로 사용되는 데이터셋들을 위주로 살펴보도록 하겠다.
MNIST(1998)
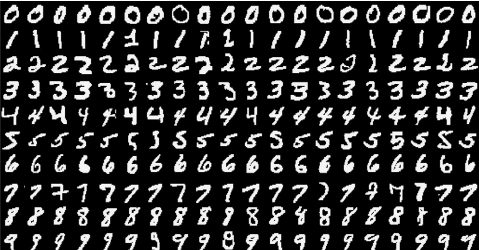
paper: Yann LeCunn Et al.(1998), Gradient-based learning applied to document recognition
MNIST 데이터셋은 손으로 쓴 숫자 이미지로 이루어진 대형 데이터셋이며, 60,000개의 Training dataset과 10,000개의 Test dataset으로 이루어져 있다.
각 데이터는 0에서 9까지의 자연수 중 하나에 대응되는 숫자에 대한 데이터이며, 하나의 데이터는 1×28×28, 총 784개의 픽셀의 색에 대한 정보를 담은 행렬이다. 각 픽셀에 대응되는 행렬의 성분은 0부터 255사이의 숫자를 가지고 있는데, 까만색에 가까운 픽셀일수록 0에 가까운 값을, 흰색에 가까운 픽셀일수록 255에 가까운 값을 가진다.
MNIST 데이터셋(Modified National Institute of Standards and Technology database)은 NIST의 샘플을 재가공하여 만들어졌다. Training set의 절반과 Test set의 절반은 NIST의 Training set에서 취합하였으며, 그 밖의 Training set의 절반과 Test set의 절반은 NIST의 Test set으로부터 취합되었다고 한다.
SVHN(2011)

SVHN은 Google Street View에서 수집된 숫자 데이터셋으로, MNIST와 마찬가지로 0부터 9까지 숫자 10개의 이미지로 이루어진 데이터셋이다. 차이점이 있다면 MNIST의 경우 손글씨에 대한 한 가지 채널의 색상(흑백)을 가진 이미지였으나, SVHN의 경우 건물 번호나 표지판과 같이 real-world에서 볼 수 있는 이미지로 이루어져 있다는 것이다. 또한, 세 가지 색상 채널(RGB)로 이루어져 있다는 차이점도 존재한다. SVHN은 73257개의 Training 데이터, 26032개의 Test 데이터로 구성되어 있다.
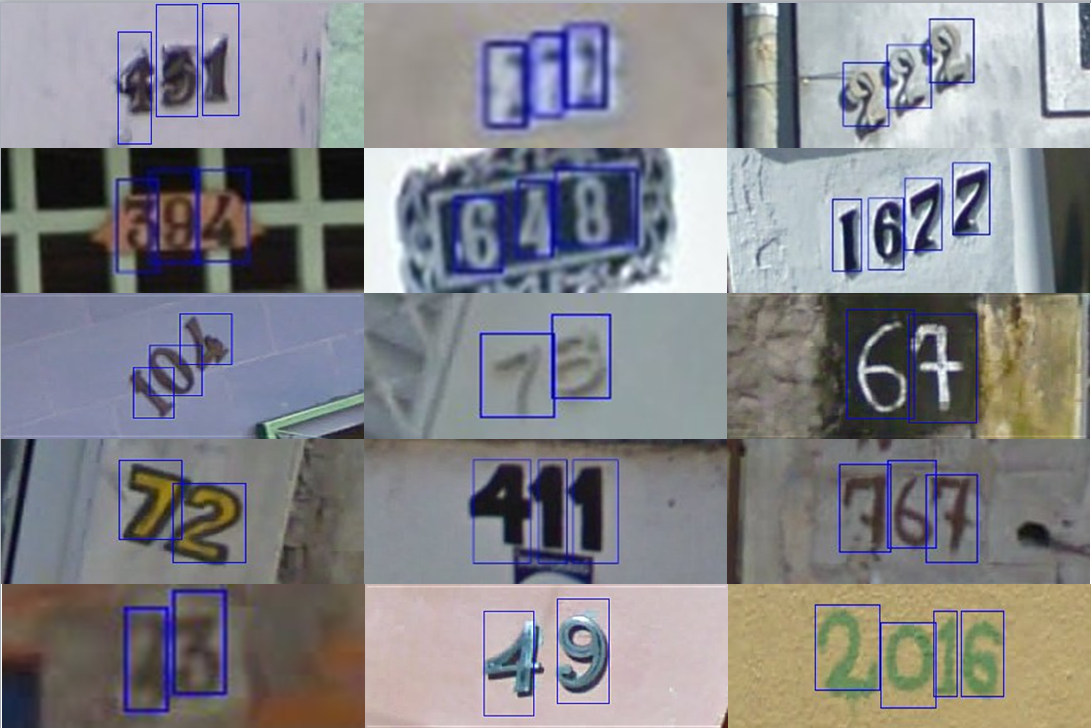
사실 SVHN format1의 경우, train.tar.gz, test.tar.gz , extra.tar.gz와 같이 train/test/extra dataset으로 나누어져 있는데, 여분의 dataset인 531,131개의 extra dataset까지 모두 합칠 경우 600,000만장이 넘는 데이터셋이 된다. extra dataset의 경우 분류 난이도가 비교적 쉬운 편이라고 한다.
format1은 각 사진마다 다른 해상도를 가지고 있는데, 학습을 위한 전처리로 $32 \times 32$ 사이즈로 crop한 SVHN format2 데이터셋이 우리가 주로 사용하는 SVHN 데이터셋이다.
CIFAR-10(2009)

paper: Alex Krizhevsky(2009), Learning Multiple Layers of Features from Tiny Images
CIFAR는 Canadian Institute For Advanced Research의 줄임말이다.
CIFAR-10과 CIFAR-100은 80,000,000만개의 tiny images dataset의 subset-data로써, Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton에 의해 수집된 데이터셋이다.
이미지의 크기는 $32 \times 32$이며, 3가지 색상 channel로 이루어져 있고, training set의 경우 50,000개, test set의 경우 10,000개의 데이터로 이루어져 있다.
Target의 label은 Airplane, Automobile, Bird, Cat, Deer, Dog, Frog, Horse, Ship, Truck와 같이 10개의 class로 구성되어 있으며, 각 class는 서로 완벽하게 차별(completely mutually exclusive)되도록 구성되었다. 즉, 어떤 데이터이든 10개의 class중 완벽하게 하나의 class에만 속하도록 구성되어 있는 것이다.
CIFAR100(2009)

paper: Alex Krizhevsky(2009), Learning Multiple Layers of Features from Tiny Images
CIFAR-100의 경우, 20개의 Supeerclass와 100개의 class로 구성된 데이터셋이며, 데이터의 수와 사이즈는 CIFAR-10과 동일하다.
Target의 경우 위와 같이 100개의 Classes로 구성되어 있으며, 그와 동시에 20개의 Superclass로 나눌 수도 있다.
사실, 이 데이터셋에는 조그마한 오류가 있는데 버섯(mushrooms)의 경우 과일/야채(fruit or vegetables)가 아니고, 곰(bears)의 경우 육식동물이 아니다. :)
ImageNet(2009)

paper: Jia Deng Et al.(2009), ImageNet: A Large-Scale Hierarchical Image Database
Stanford University의 Li Fei-Fei 교수를 중심으로 제작되었으며, Google, Microsoft와 같은 기업 또한 함께 참여하여 제작한 데이터셋이다.
ImageNet Dataset의 경우, ILSVRC: ImageNet Large Scale Visual Recognition Competition 에서 사용되는 데이터셋으로 유명하다.
총 21,841개 classes의 14,197,122개 데이터로 구성되어 있으며, 다양한 해상도의 image size로 구성되어 있다. 데이터셋 구성 내역에 대한 자세한 설명은 이곳의 설명을 참고하면 된다.
보통 $227 \times 227$ pixels로 crop된 sub-sampled images를 사용하는 것이 일반적이다.
STL-10(2011)

STL-10은 ImageNet 데이터셋의 labeled data에서 sampling하여 만든 데이터셋이며, 5,000개의 training 데이터와 8,000개의 test 데이터로 이루어져 있다. Unsupervised learning을 위한 labeling이 되어있지 않은 100,000개의 data 또한 함께 포함되어 있다.
STL-10의 경우, $96 \times 96$ 크기의 해상도로 MNIST/SVHN/CIFAR10/CIFAR100에 비하여 비교적 큰 해상도를 가지고 있다.
Reference
THE MNIST DATABASE of handwritten digits
The Street View House Numbers (SVHN) Dataset
ImageNet: A Large-Scale Hierarchical Image Database, Jia Deng at el., 2009]