우선, 해당 포스트는 Stanford University School of Engineering의 CS231n 강의자료를 기본으로 하여 정리한 내용임을 밝힙니다.
ILSVRC
ILSVRC는 2010년부터 2017년까지 개최된 ImageNet dataset에 대한 Image Recognition(Classification) 대회이다. ImageNet dataset에 대한 설명은 이 포스트에 정리해 두었다.

ImageNet 데이터셋에 대한 Image Classification Task의 경우 이미 2015년부터 인간의 Error Rate(5.1%)를 뛰어넘어 3.6%에 도달하였으며, 마지막 대회인 2017년의 경우 2.3%의 Error Rate를 달성하게 된다.
이번 포스트에서는 최초로 CNN 기반의 모델로 우승을 거머쥔 AlexNet(2012)과 이를 발전시킨 모델인 ZFNet(2013)을 살펴보도록 하겠다.
AlexNet(2012)
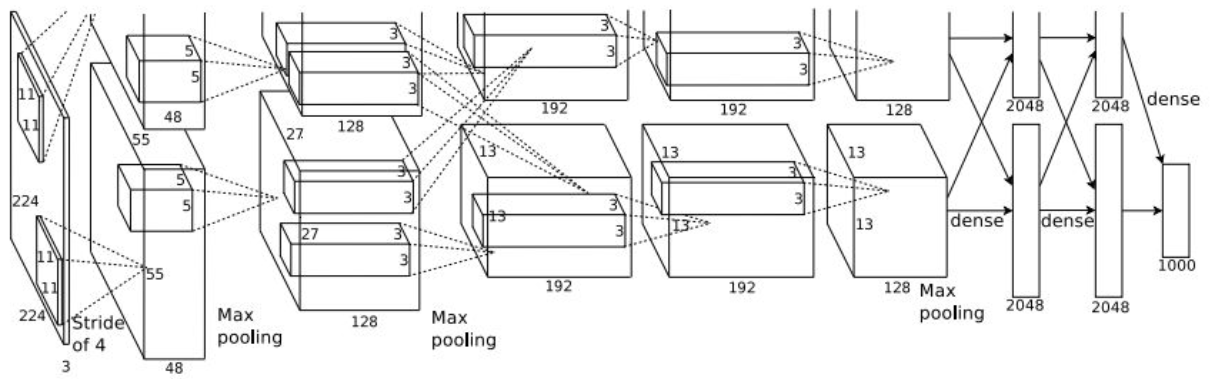
paper: Krizhevsky et al.(2012), ImageNet Classification with Deep Convolutional Neural Networks
위 그림이 살짝 짤려있는데 그림을 잘못 가져온 것이 아니라, 원래 논문에 이렇게 들어가 있다. 또한, 위 그림에서는 224로 되어있지만 오타로 알려져 있으며, input의 크기는 $227 \times 227 \times 3$을 받는다고 생각하면 된다.
이제 Output의 dimension을 생각해보도록 하자.
첫 번째 Layer(CONV1 Layer)에서는 intput size가 227, filter size가 11 $\times$ 11, Stride가 4로 총 96개의 filter가 적용되었다. 따라서, 다음과 같이 output dimension $55 \times 55 \times 96$을 계산할 수 있다.
\[{(227-11) \over 4} + 1 = 55\]덧붙여 이 Layer(Convolution filter)의 parameter의 수는 $11 \cdot 11 \cdot 3 \cdot 96 = 34,848$개 임을 알 수 있다.
두 번재 Layer를 살펴보도록 하자. 두 번째 Layer의 경우 input size가 55, filter size가 3 $\times$ 3, Stride가 2가 적용되었다. 따라서 다음과 같이 ouput size $27 \times 27 \times 96$을 계산할 수 있다.
\[{(55-3) \over 2} + 1 = 27\]참고로 이 Layer(Pooling Layer)는 Weight을 가지지 않으며, 따라서 parameter의 수는 없다.
이와 같은 방식으로 모든 Layer에서의 output dimension를 계산해보면 다음과 같다.
결과적으로 AlexNet의 $227 \times 227 \times 3$의 input을 주면, ImageNet dataset의 class 수인 1000개의 class scores가 나오도록 구성되어 있는 것을 확인할 수 있다.
참고로 NORM1/NORM2라는 Normalization layer가 눈에 띄는데, 해당 논문이 나온 2012년 당시에는 많이 사용되곤 하였던 Layer지만, 이후에는 해당 Layer의 효용성이 낮다고 판단하여 더이상 사용되지 않고 있는 Layer 종류이다.

AlexNet의 역사적으로 중요한 의미를 가지는데, AlexNet은 최초로 ReLU를 사용한 Convolutional Neural Networks이기 때문이다. AlexNet의 경우, 모든 Convolution Layer와 Fully Connected Layer에 Activation function으로 ReLU 함수를 사용하였다.
또한 AlexNet은 flipping, jittering, cropping corlor normalization 등의 다양한 Data Augmentation을 사용하여 성능을 향상시켰다.
ZFNet(2013)
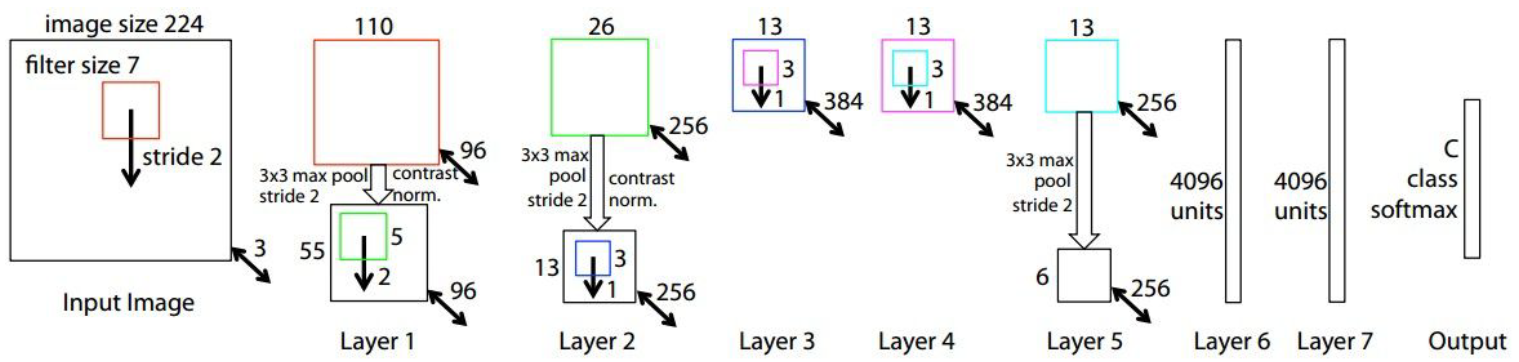
paper: Zeiler and Fergus(2013), Visualizing and Understanding Convolutional Networks
ZFNet은 기본적으로 AlexNet과 아주 유사한 구조를 가지고 있다.
첫 번째 다른 점은 CONV1 layer에서 AlexNet(2012)의 경우 $11 \times 11 \text{ size filter with stride } 4$를 사용하였으나,
ZFNet(2013)의 경우 $7 \times 7 \text{ size filter with stride } 2$를 사용하였다는 점이다.
두 번째 다른 점은 CONV3, CONV4, CONV5 Layer의 filter의 개수이다. AlexNet의 경우 384, 384, 256개의 filter를 사용하였으나, ZFNet의 경우 512, 1024, 512개의 filter를 사용하였다.
즉, Convolutional Layer에서 Filter의 크기는 줄이면서, 개수를 늘리는 방향 hyper parameters를 조정하여 AlexNet을 개선한 것이라고 볼 수 있다.
Zeiler는 Clarifai라는 회사를 세우고, 이 회사의 이름으로도 대회에 참여하여 11.7%까지 error를 낮춘 모델을 선보인다. 이로써 AlexNet의 top 5 error(16.4%)를 뛰어넘게 되고, ILSVRC 2013에서 우승을 차지하게 된다.
Reference
Krizhevsky et al.(2012), ImageNet Classification with Deep Convolutional Neural Networks
Zeiler and Fergus(2013), Visualizing and Understanding Convolutional Networks