우선, 해당 포스트는 Stanford University School of Engineering의 CS231n 강의자료를 기본으로 하여 정리한 내용임을 밝힙니다.
ILSVRC’14
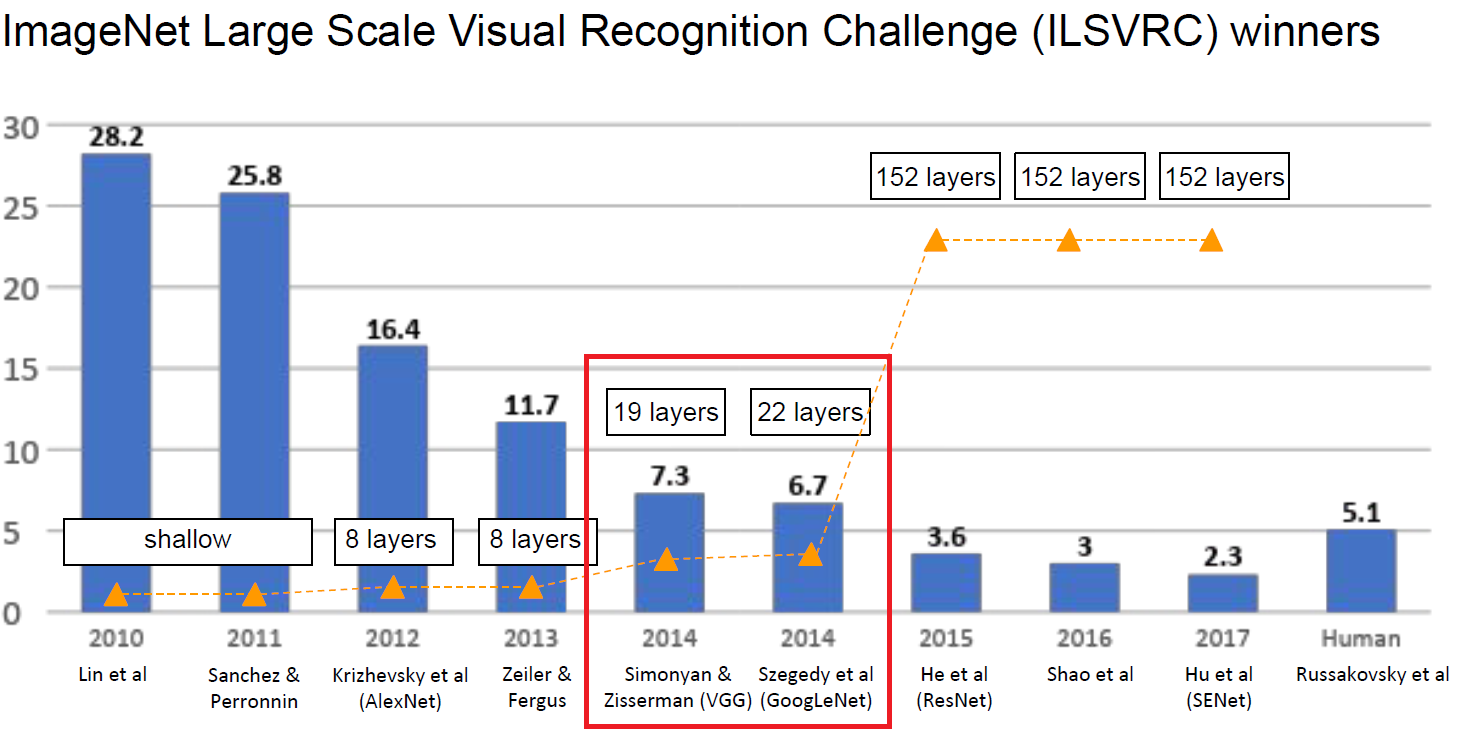
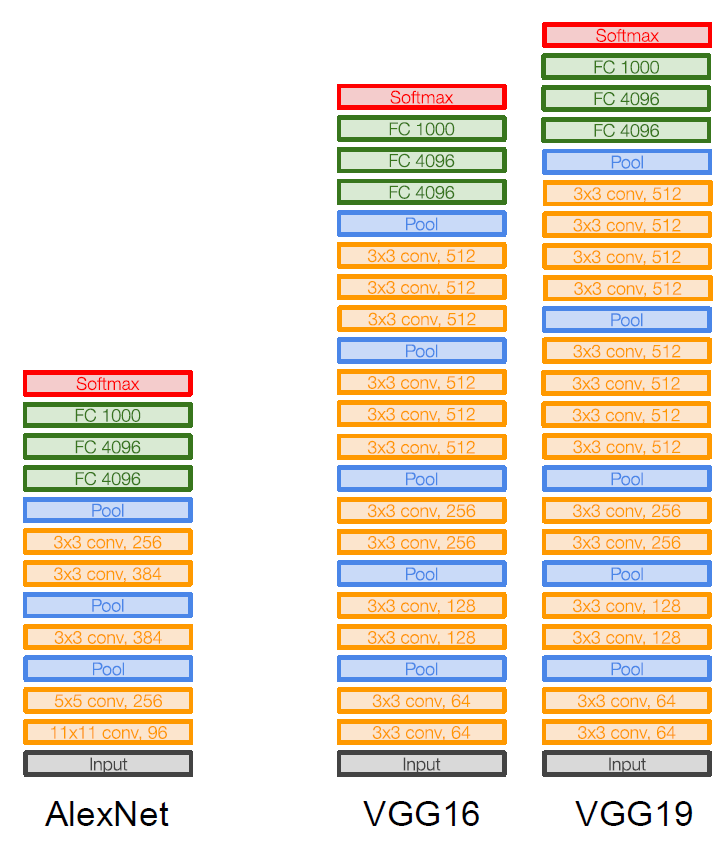
이번 포스트에서 살펴볼 모델은 ILSVRC’14의 Classification task에서 각각 2등과 1등을 차지한 VGGNet와 GoogLeNet이다. 그 중, 먼저 살펴볼 VGGNet의 경우 ILSVRC’14 Classification task에서는 2등, Localization task에서는 1등을 차지한 모델이다. VGGNet의 구조는 다음과 같다.
VGGNet(2014)
paper: Simonyan and Zisserman(2014), VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
VGG의 경우 앞선 포스트에서 살펴본 LeNet, AlexNet, ZFNet과는 확연히 다른 점이 존재한다.
우선 VGG의 경우 Conv Layer와 Pooling layer의 Filter size를 일괄적으로 통일시켜 주었다. 앞서 살펴본 다른 모델들의 경우 Conv Layer마다 Filter size를 바꿔주었는데, VGGNet의 Convolutional Layer들은 Filter size를 $3 \times 3 \text{ with stride 1, pad 1}$으로 고정시켰다.
$3 \times 3$의 작은 filter를 사용하는 것이 상당히 눈에 띄는데, VGGNet은 더 많은 수의, 더 작은 크기의 filter를 사용한다. 예를 들어, 3개의 $3 \times 3$ filters는 1개의 $7 \times 7$ filter와 같은 effective receptive field를 가지게 된다. 이로써 더 깊지만 더 적은 수의 parameter를 가지는 convolutional layer를 만들 수 있게 된다. 실제로 계산해 보면, $3 \times 3^2 \times \text{(# of channels)}$는 $1 \times 7^2 \times \text{(# of channels)}$보다 더 적은 수임을 확인할 수 있다. Convolution layer뿐만 아니라, Pooling layer의 filter size 또한 일괄적으로 $2 \times 2 \text{ with stride 2}$로 통일시켜 준 것을 확인할 수 있다.
각 Layer마다 소요되는 Memory와 parameter의 수를 살펴보면 다음과 같다.

VGGNet의 경우 전체적으로 모델의 뒷단으로 갈수록 feature map의 size는 점차 줄어들면서 filter의 개수는 점차 늘어나도록 구성되어 있다는 특징을 가지고 있다.
VGGNet의 첫 번째 FC Layer의 parameter의 개수를 눈여겨 볼 만 한데, 하나의 layer에서 약 1억개에 육박하는 parameter를 가지고 있는 것을 확인할 수 있다. 이 때문에 굉장히 비효율적인 training이 이루어지게 되며, overfitting을 해결하는데에도 전혀 도움을 주지 못한다.
VGGNet은 7.3%의 error rate로 ILSVRC 2013 Clarifai’s ZFNet의 11.7% top-5 error rate를 넘어서면서 ILSVRC 2014에서 2등을 차지하게 된다.
GoogLeNet(2014)
paper: Szegedy et al.(2014), Going deeper with convolutions
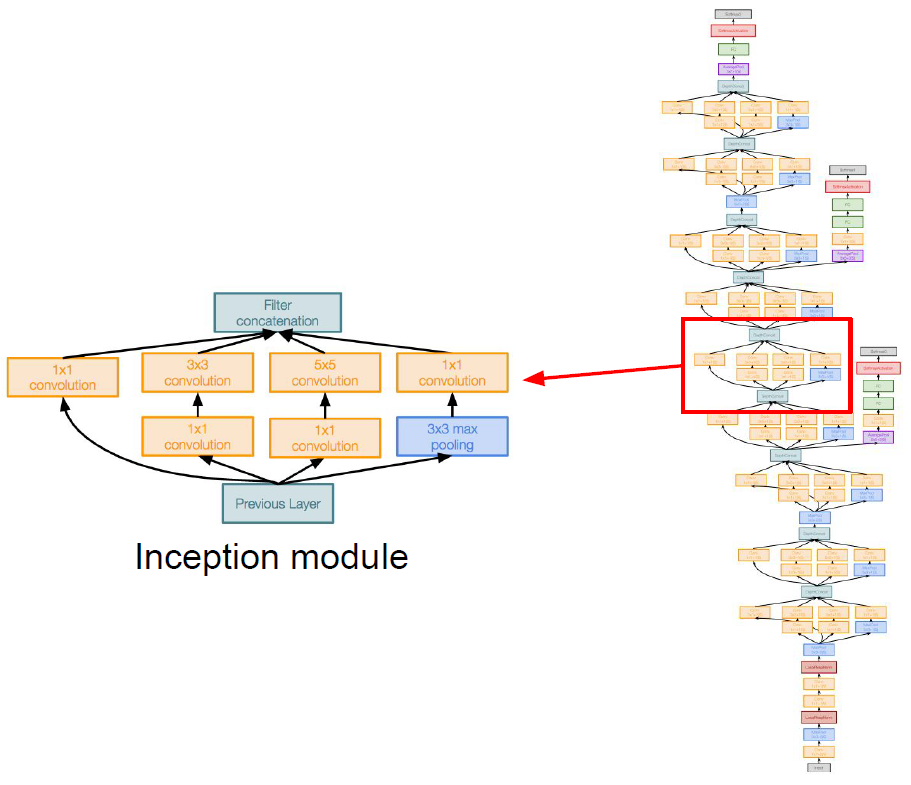
GoogLeNet은 위와 같이 매우 복잡한 구조를 가지고 있다. 하지만 부분 부분 살펴보면, 여러개의 Inception module로 이루어져 있다는 것을 확인할 수 있다.
하나의 Inception module을 떼어서 살펴보면 다음과 같다.
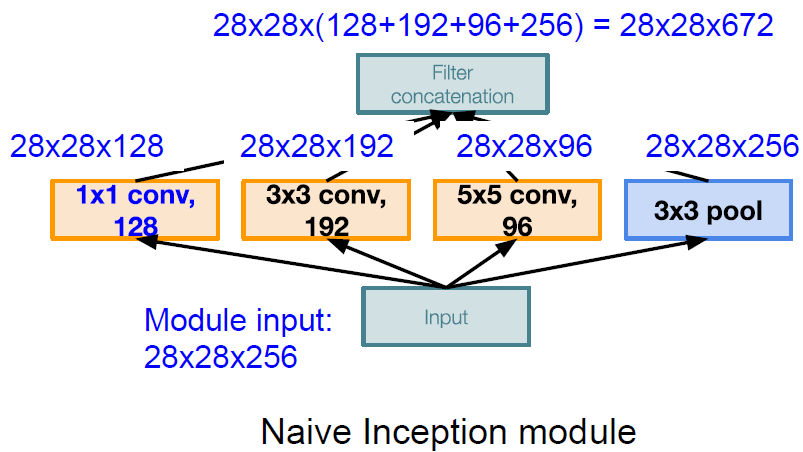
GoogLeNet의 경우 Computationally complex하다는 단점이 존재한다. 실제로 위 그림에서 Filter Concatenation을 거쳐 나온 output의 dimension은 $28 \times 28 \times 672$가 되고, 이는 다음 inception module의 input이 된다. 여기서 계산해야하는 총 parameter의 수는 8억 5400만(854M)으로써 매우 많다는 것을 확인할 수 있다.

GoogLeNet은 Inception module에 Bottleneck layers를 도입하여 이러한 문제를 해결하게 된다. Bottleneck layer는 $1 \times 1$ convolutional layer를 의미하는데, 이를 사용함으로써 다음과 같이 dimension reduction 효과를 볼 수 있게 된다.
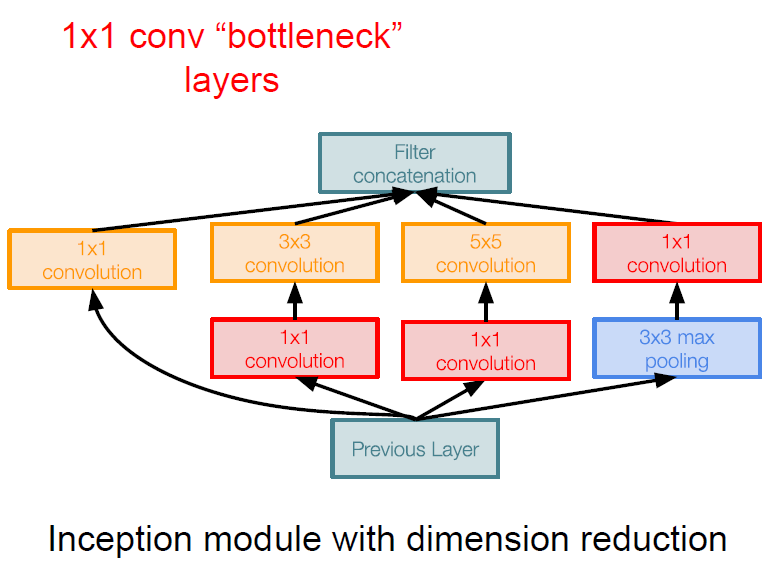
결과적으로 dimension reduction을 적용한 Inception module에서는 다음과 같이 3억 580만(358M) 개의 parameter를 가지게 되고, 이는 앞서 살펴본 개수보다 훨씬 줄어든 수임을 알 수 있다.
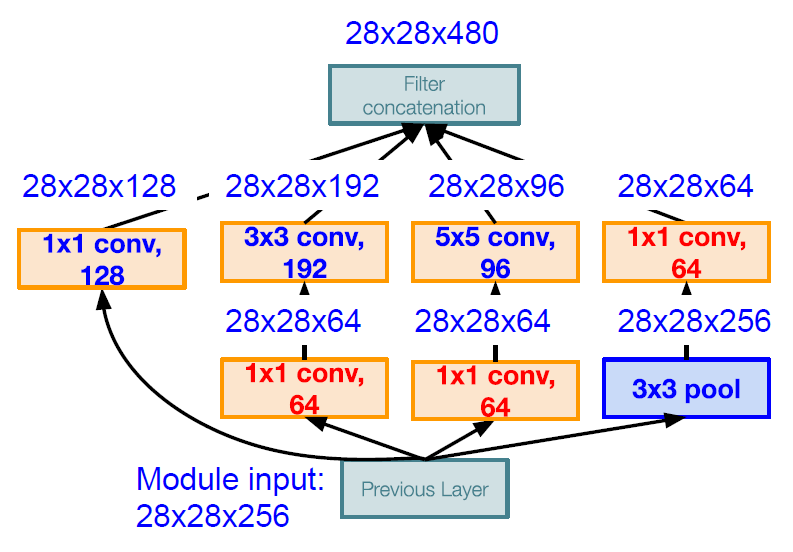
사실 Dimension reduction을 통하여 어느정도의 정보의 손실이 발생할 수 밖에 없지만, 이로 인해 잃는 것보다 각 Feature map들 간의 Linear combination을 통하여 얻을 수 있는 Nonlinearity의 장점이 더 크기 때문에 성능 또한 좋아지게 된다.
한 가지 주목할 만한 점은 마지막 단에서 FC Layer를 완벽하게 제거하고, Average Pooling Layer를 대신 사용하였다는 점이다. 앞서 살펴보았던 VGGNet의 경우 FC Layer의 과도한 Parameter의 수가 단점이 되었는데, GoogLeNet의 경우 FC Layer를 Average Pooling Layer로 대체해줌으로써 Parameter의 수를 훨씬 더 줄일 수 있게 된다. 그 결과 AlexNet은 6000만 개(60M), VGGNet(VGG16)은 1억 3800만 개(138M)의 parameters를 가지고 있는 것에 비하여 GoogLeNet은 겨우 5백만 개(5M)의 parameters밖에 가지지 않게 된다.
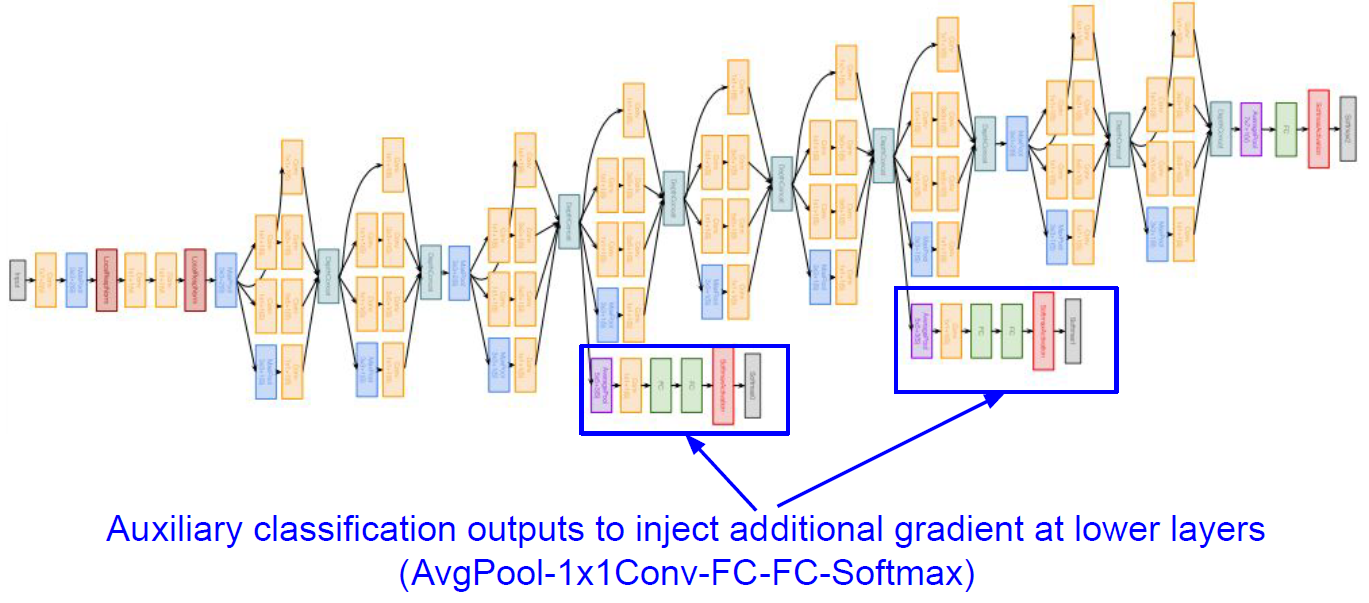
한 가지 눈에 띄는 GoogLeNet의 특징은 lower layers에서 추가적인 gradient를 반영해주기 위하여 만들어준 Auxilary classification outputs이 존재한다는 것이다.
여기에서는 모델의 중반 부분에서 따로 끊어서 마치 모델의 마지막 부분인 것처럼 FC Layer와 softmax를 거쳐 output을 만들어 준다. 이렇게 추가적으로 gradient를 계산할 수 있도록 만들어준 이유는 GoogLeNet이 아주 깊은 depth를 가지고 있기 때문이다.
Networks가 너무 깊을 경우, 마지막 loss term에서의 계산에서 시작되는 back propagation 과정은 gradients 중 일부의 signal을 약하게 만들 우려가 존재한다. 이를 방지하기 위하여 비교적 모델의 앞단에서 추가적으로 gradient 계산을 도울 수 있도록 만들어 준 것이라고 생각하면 된다.
GoogLeNet의 경우 ILSVRC 2013의 11.7% top-5 error 기록을 6.7%로 갱신하며 ILSVRC 2014에서 우승을 차지한다.
다만 위와 같이 GoogLeNet의 매우 복잡한 구조에 비하여, 2등을 기록하였지만 훨씬 더 간단한 구조의 VGGNet을 일반적으로 더 많이 사용하는 경향이 있다.
Reference
Simonyan and Zisserman(2014), VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION